
This is part 1 of a 4-part series on The Making of Manhattan’s Coffee Kings.
For the Gramener data storytelling hackathon this month, I planned to tell the story of which coffee store covered the highest population in Manhattan.
This was not an accidental choice. I wanted something that’s map-based. I wanted to merge census data into maps. I also wanted something interesting enough to be marketable.
I read about the fight Starbucks has been facing from the likes of Dunkin’ Donuts and McDonald’s, and decided to write about it.
Planning
I had 4 days before the hackathon, so the planning had to be meticulous. I checked with the hackathon team and confirmed that scraping the data and pre-planning the story was within the rules, as long as I executed the story on the day of the hackathon.
The plan was as follows:
- Get the data (8 July)
- Get the Manhattan census map
- Get the Manhattan census population data
- Get coordinates for coffee shops in Manhattan
- Create the maps (9 July)
- Create the coffee shop coverage region map
- Merge census population data into the coverage map
- Write the story (10-11 July)
- Write down the insights as a storyline
- Plan a format and design
- Implement a version of this in Power BI (to showcase at Microsoft Inspire)
I could do all of these except the design and Power BI implementation. I’m not good at either. So I asked for help. My colleagues Devarani & Navya volunteered. Forming the team early helped a lot since we could plan well.
Luckily, we followed the plan almost perfectly, except that “Create the maps” took 2 days instead of 1, so we had only 1 day to “Write the story”. But that didn’t cause a problem.
Get the data
Getting the Manhattan census map and population data didn’t take much time. Both were on NYC.gov.
Scraping the stores’ location data took a bit of time. Using Chrome’s Developer Tools > Network., I found that McDonald’s store locator uses an API at https://www.mcdonalds.com/googleapps/GoogleRestaurantLocAction.do It accepted a radius= and maxResults= parameter. But increasing both, I was able to write a quick script that fetched the 1,000 closest stores within a 50 mile (or is it kilometer?) radius.
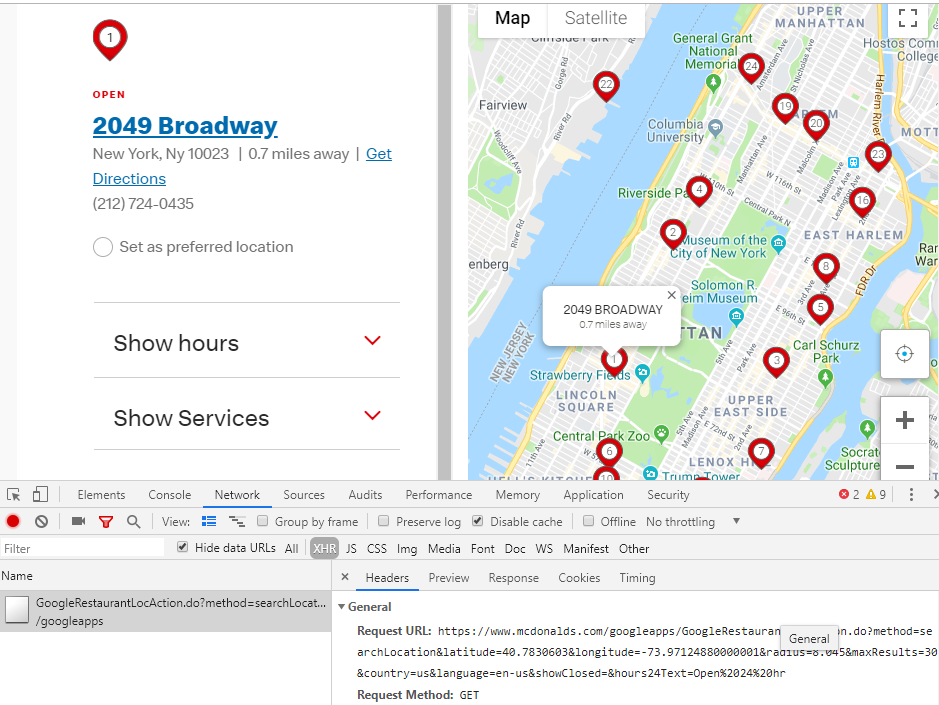
Starbucks’ store locator was trickier. The API returns stores around a ?lat= and a ?lng=, but there was no obvious way to increase the number of stores. It also does not allow direct access. It must be accessed via XHR.
Rather than solve this elegantly, I just manually moved the store locator map around to cover all of Manhattan and noted the locations. Then I created a script that collates all of these JSON responses together.
I tried scraping Dunkin’ Donuts’ website but got an Access Denied. It let them know, but it’s still down. So I assumed that they won’t last long, and moved on with just two stores.

At this point, we had all the data and were ready to create the maps.