

Large Language Model (LLM) hallucinations in GenAI are like the digital daydreams of the AI world. They’re the moments when your computer thinks it’s the star of a sci-fi movie and starts conversing with intergalactic space llamas. 😀
But its serious though!
BTW our Citizens of Comicgen are literally goofing around with LLMs.

Table of Contents
What are LLM Hallucinations?
Did you know the occurrence of hallucinations in LLMs, with an estimated prevalence of 15% to 20% in ChatGPT, can significantly impact a company’s reputation?
Hallucinations in this context refer to the generation of information that is not based on factual or real-world knowledge but is instead created by the model itself.
Below are several key findings on LLMs and their abilities in memorization, generalization, and natural language inference tasks, per the research study conducted by the University of Edinburgh and Macquarie University.
Memorization and Generalization
- LLMs can memorize extensive data, especially when compared to smaller language models.
- The text highlights that entity recall and the frequency of terms in training data significantly affect generalization in LLMs.
- LLMs focus on numbers and nouns during early training, potentially serving as unique sentence identifiers.
Understanding Prompts
- LLMs perform surprisingly well on NLP tasks, even with poorly formulated prompts, raising questions about how LLMs interpret prompts compared to humans.
- The tasks designed for language inference may sometimes be tackled as memory recall tasks by LLMs, potentially leading to correct answers.
GPT-4’s Understanding
- GPT-4 possesses a deep and flexible understanding of language beyond mere memorization.
- However, GPT-4, like other LLMs, is susceptible to hallucinations, implying limitations in their comprehension capabilities.
Factors Influencing LLM Performance
- Two critical factors affecting LLM performance in natural language inference tasks: the recall of memorized information and the use of corpus-based heuristics (strategies or decision-making processes that are based on statistical patterns and information extracted from a large and structured collection of text or language data), such as term frequency.
- The apparent reasoning capability of LLMs can be attributed to these factors, which originate from model pretraining.

How Far Can I Trust A Language Model
In his recent interview featured in Analytics India Magazine, Anand delves into the pressing issue of trust surrounding language models, particularly large ones such as GPT-3. The conversation highlights the remarkable abilities of these models to generate text resembling human speech, yet it raises crucial concerns about their reliability, possible biases, and ethical consequences.
Types of LLM Hallucinations
Factual Inaccuracy
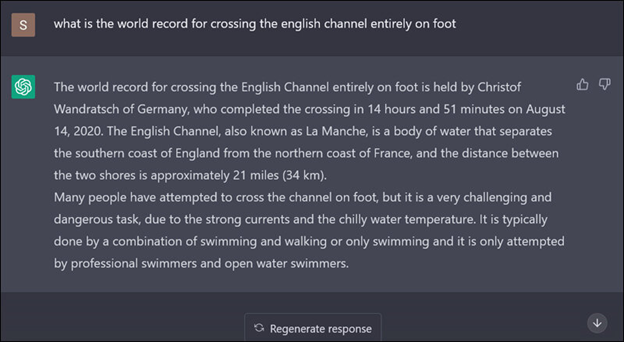
The model generates factually incorrect information, just like the following screenshot.

Invented Details
The model creates details or facts that do not exist, like describing a non-existent animal or a fictional event in history.
Bias Amplification
LLMs can inadvertently amplify existing biases present in their training data, leading to the generation of biased or prejudiced content.

Why Does LLM Hallucinations Happen?
The hallucination phenomenon in LLMs happens due to:
Data Biases
LLMs are trained on vast datasets from the internet, which can contain biased, false, or misleading information. These biases can propagate into the model’s generated text.
Ambiguity Handling
LLMs struggle with ambiguity and may generate content when faced with unclear or imprecise input, often filling in gaps with invented information.
Over-optimization
Some LLMs, during training, may over-optimize for certain objectives (e.g., maximizing output length) and generate verbose, irrelevant, or hallucinated responses to meet those objectives.
As per IBM the three major reasons for LLM hallucinations are:
Data Quality
- Training Data Noise: LLMs are typically trained on vast datasets compiled from the internet, which can contain noisy, biased, or incorrect information. If the training data includes misinformation, factual inaccuracies, or biased content, the model may learn and replicate these errors. Consequently, when generating text, the LLM can produce hallucinated content that aligns with the inaccuracies present in its training data.
- Ambiguous or Contradictory Data: Inconsistent or contradictory information in the training data can confuse the LLM. When faced with ambiguous or conflicting context, the model may generate responses that are arbitrary or inaccurate because it lacks clear guidance from its training data. These inconsistencies in the data can lead to hallucinations.
- Lack of Contextual Verification: LLMs do not possess the ability to verify information against external sources or access real-time data. They generate responses based solely on patterns learned during training. If the training data contains outdated information or lacks context, the model may generate responses that are outdated or contextually irrelevant, contributing to hallucinations.
- Bias in Training Data: Data used to train LLMs can contain inherent biases, stereotypes, or controversial opinions. These biases can be learned and perpetuated by the model, leading to responses that reflect those biases even when they are not appropriate or accurate in each context. This can result in hallucinated responses that reinforce existing biases.
- Lack of Diverse Data Sources: Training data for LLMs may not be representative of all perspectives and domains of knowledge. If the data sources are limited or biased towards certain viewpoints, the model may not have a well-rounded understanding of various subjects, leading to hallucinations when responding to diverse or less common topics.
- Rare or Uncommon Scenarios: LLMs may not have encountered rare or uncommon scenarios during their training. When faced with such scenarios in the input context, the model may lack the necessary information to provide accurate responses, potentially leading to hallucinated or nonsensical content.
- Data Anomalies and Outliers: Anomalies, outliers, or errors in the training data can impact the model’s understanding and behavior. If the model learns from such anomalies, it may generate responses that are inconsistent with normal expectations, resulting in hallucinations.
Generation Method
- Autoregressive Nature: Many LLMs, including those based on the GPT architecture, are autoregressive models. This means they generate text one token (word or sub-word) at a time, with each token being conditioned on the preceding tokens. While this approach allows LLMs to produce coherent and contextually relevant text, it can also lead to hallucinations when the model generates tokens that are inconsistent with the context or input. The model may make predictions based on its own previous incorrect or biased tokens, resulting in hallucinated content.
- Sampling Strategies: LLMs often employ different sampling strategies during text generation, such as greedy decoding, beam search, or random sampling. These strategies can influence the diversity and quality of generated responses. In some cases, overly conservative or greedy sampling strategies can cause the model to produce safe, generic responses that may be contextually inaccurate but with less hallucination. On the other hand, more exploratory sampling methods can result in hallucinations when the model generates creative but incorrect or nonsensical content.
- Temperature and Top-k/Top-p Parameters: LLMs allow users to adjust parameters like “temperature” and “top-k” or “top-p” to control the randomness and diversity of generated text. Higher temperature values or looser top-k/p thresholds can lead to more randomness and creativity in responses, but they can also increase the likelihood of hallucinations as the model may produce unexpected or out-of-context content.
- Lack of Ground Truth Validation: LLMs do not have access to an external source of truth to validate the accuracy of their responses. They rely solely on their training data and the context provided in the input. If the model encounters ambiguous or poorly defined context, it may rely on its training data and generate content that is factually incorrect or hallucinated.
- Fine-tuning and Post-processing: In some cases, LLMs are fine-tuned on specific tasks or domains, and post-processing techniques are applied to make their responses more coherent or contextually relevant. However, if the fine-tuning or post-processing is not well-implemented or is biased, it can introduce errors or hallucinations into the generated text.
Input Context
- Insufficient or Ambiguous Context: LLMs rely heavily on the input they receive to generate responses. If the input context is incomplete, unclear, or ambiguous, the model may fill in the gaps with information that is incorrect or fabricated. This can lead to hallucinations because the model is essentially making assumptions to complete the context.
- Misinterpretation of Context: LLMs can misinterpret the input context due to the complexity of language and the limitations of their training data. If the model misunderstands the context, it may generate responses that are relevant to the misinterpreted context but are factually incorrect. This is another way in which hallucinations can occur.
- Overfitting to Training Data: LLMs are trained on large datasets from the internet, which can contain incorrect or biased information. If the model overfits to this training data and assumes that certain incorrect information is true, it may generate hallucinated responses that align with those inaccuracies.
- Lack of Real-world Knowledge: LLMs have a knowledge cutoff date beyond which they do not have access to new information. If the input context involves recent events or developments that occurred after the model’s knowledge cutoff date, it may generate responses based on outdated information or assumptions, leading to hallucinations.
Implications of Hallucination in LLMs
- Misinformation Spread: One of the most significant concerns surrounding hallucination in LLMs is the potential for the spread of misinformation. Users may unknowingly trust and propagate false or invented information generated by these models.
- Ethical and Societal Concerns: Hallucination can amplify biases and stereotypes in training data, perpetuating social and ethical problems like discrimination, misinformation, and harm.
- Trust and Reliability: Hallucination undermines trust in AI content, potentially reducing reliance on LLMs for information or decision-making, and impeding AI adoption in critical domains.
How to Fix LLM Hallucinations
Addressing hallucination in LLMs is a complex challenge, but several strategies can help you mitigate its impact:
Improved Training Data
Efforts to clean and diversify training data can help reduce biases and misleading information in LLMs’ knowledge base.
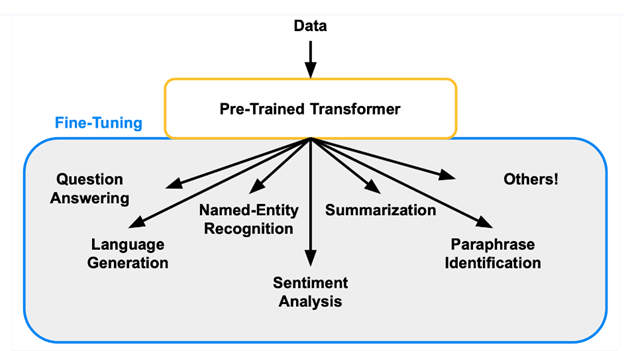
Fine-tuning
Fine-tuning LLMs on specific tasks and datasets can help make them more contextually accurate and less prone to hallucination.
Multi-shot prompting
Provide several examples to enable the LLM to learn from diverse instances. Multi-shot prompts are vital for complex tasks, providing diverse examples that enhance LLM understanding. Use them when one instance isn’t enough or when showcasing patterns or trends.

Clear and Specific Prompts
- Prompt Engineering: Crafting clear and precise prompts or queries can guide LLMs to generate more accurate and relevant responses.
- Ethical Guidelines: Developers should adhere to ethical guidelines that prioritize fairness, transparency, and accuracy when training and deploying LLMs.
- Post-processing Filters: Implementing filters and review mechanisms to identify and correct hallucinated content in LLM-generated text.

Conclusion
The hallucination phenomenon in LLMs highlights the need for ongoing research and development in artificial intelligence. While these models exhibit remarkable capabilities, they pose significant challenges regarding reliability, accuracy, and ethical concerns. Efforts to mitigate hallucination, such as improving training data and fine-tuning models, are steps in the right direction. However, comprehensive solutions demand collaboration among researchers, developers, and policymakers, to maximize LLMs’ societal benefits while minimizing bias and misinformation.
