

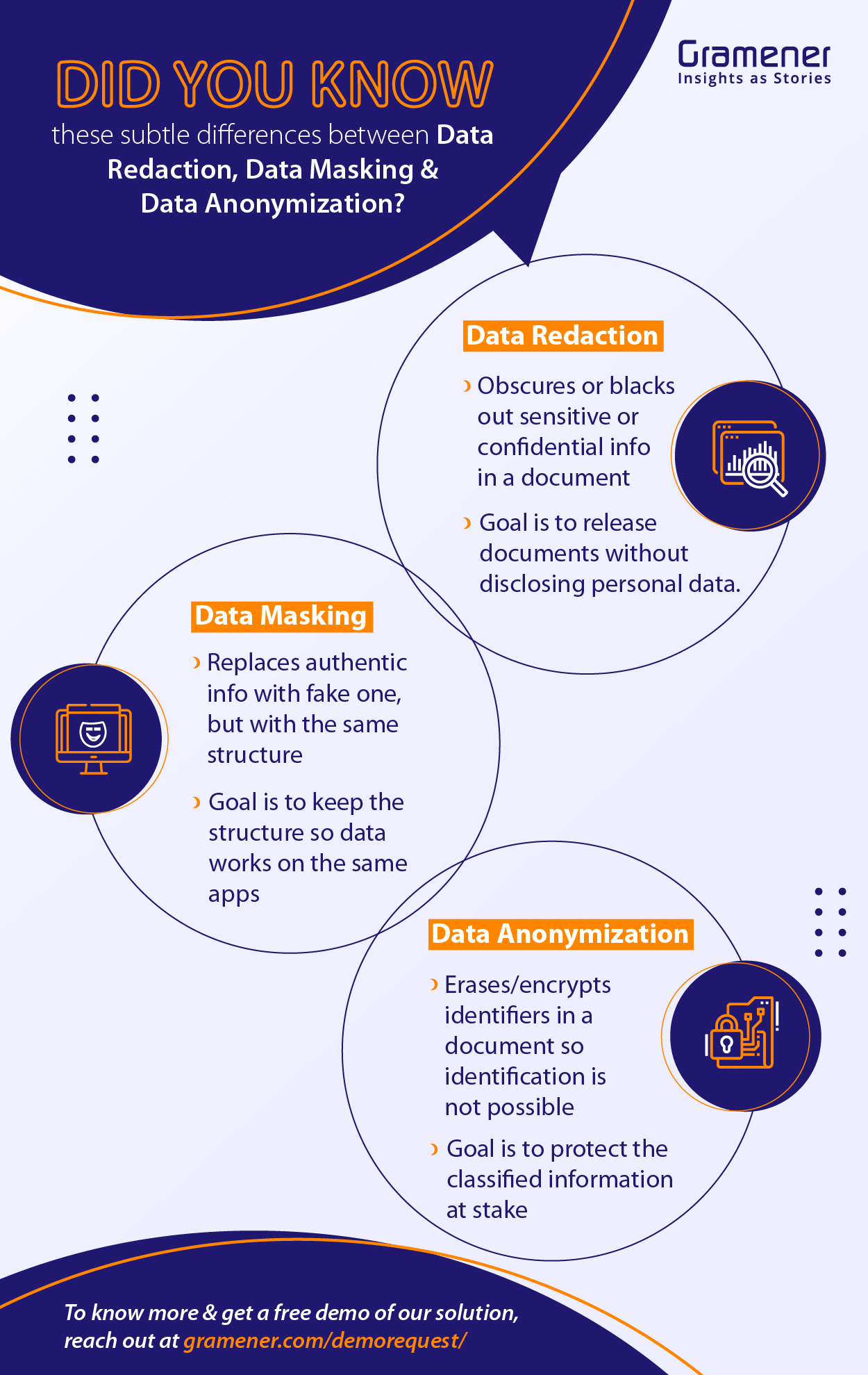
Businesses in this digital era increasingly rely on technology for their regular operations. There is an enormous amount of data generated in the process, some of which are personal and sensitive. Personal data can help businesses gain insights into customer preferences and customize their offerings. Through data anonymization, identifiers that link individuals to stored information are removed or encrypted, protecting confidential information. Fintech is one of the prime examples of how financial service providers personalize their solutions to offer the desired products to their clients.
Data sharing between digital media platforms and businesses is a win-win situation for both parties. It helps consumers get better offers that suit their needs. However, this data has to be kept anonymized to protect user information.
Data anonymization is one such technique that helps make this possible. There are many data anonymization tools available to encrypt any personal identifying information such as name, phone number, date of birth, credit card number etc. This article looks at data anonymization, its techniques, pros and cons, and more.
Table of Contents
What is Data Anonymization?
Data anonymization involves safeguarding personal and sensitive user information. It happens by encrypting and erasing identifiers related to individuals and associated data. Let us assume you have a database of 1000 people with their names, addresses, and social media handles.
When you run the data through the anonymization process, the source will remain anonymous, and you will still have the data intact. But some de-anonymization techniques can breach the protection by retracing the anonymization process. It happens when attackers cross-reference public data sources to access personal information.
When it comes to the GDPR (General Data Protection Regulation) regulations, businesses can collect anonymized data without any need for individual consent. Organizations can gather, store, and use it for as long as they want. The only consideration is that they need to remove identifiers from the data.
How is Data Anonymization Different from Data De-Identification?
Data de-identification is a data minimization technique and differs from the anonymization process. Businesses do not always have the option of anonymizing data based on personalization and customization needs.
For example, if you download software that needs your personal information to run smoothly, but the data goes through the anonymization process, you may no longer run the software successfully.
Similarly, businesses that use machine learning models for recommendations do not need personally identifiable information. They only need de-identified data without knowing to whom the data belongs.
De-identified information can also bring with it a few disadvantages. When users ask businesses to delete their data, they must delete it from all sources. It becomes difficult to understand what information you want to delete if this is de-identified data.
The best way to overcome the problem associated with de-identified information is to delete the entire dataset at regular intervals. Businesses can have some datasets that need to exist only for a limited duration, like analytics-related server logs.
Various Data Anonymization Techniques
Here are the various ways you can anonymize data:
Data Masking
Detection and reverse engineering will not work when you mask data. It involves hiding data through altered values. Users can create a duplicate database and apply modification techniques like word and character replacement, encryption, and shuffling.
Pseudonymization
It is a data de-identification method that involves replacing private identifiers with pseudonyms. For instance, if Henry Williams is an identifier, you can change it with another name, Adam Smith. You can still expect complete integrity and accuracy of data. The modified data remains ideal for testing, training, and other purposes.
Generalization
It involves removing some data to reduce its identifiability. For example, a house address may have an apartment number, street name, city, and state. You can remove personal and identifiable information like apartment numbers and city names. Despite removing a few elements, the overall data will remain accurate for use.
Data Swapping
It involves swapping the attribute values in a dataset. They will not match with the original records when you do this step. Some common attributes can be the date of birth and name that you can anonymize. It will lead to better anonymization of datasets.
Scrambling/Shuffling
Cryptographic data scrambling is one of the most popular use cases here. It involves shuffling the letters or digits in an attribute. For example, if you have a date of birth of 31121980, you can change it to 21318019. The data cannot be retrieved as the entire process is irreversible.
Blurring
Blurring is an approximation technique to reduce the originality of information slightly. It involves making the dataset less precise to minimize the chances of identification. The values will not change significantly, but the data of individuals will become anonymous.
Data Encryption
It is one of the best data anonymization techniques that renders information unreadable. You can use this method to transform personal data into a coded form, making it unreadable for anyone. Only approved users can retrieve the data into an original format and read it by accessing it with the help of a password.
When we combine data encryption with the cloud, there is a range of benefits for businesses. You will protect the data from breaches and meet regulatory and compliance norms. Your data will also remain safe from accidental exposure or breaches by cloud service providers. When your remote data becomes secure, outsourcing of tasks also becomes simple.
Gramener’s NLP Approach to Data Anonymization
Clinical trial documents can run into thousands of pages. They are submitted to regulatory authorities such as the FDA for approval. To ensure that these documents do not carry the participants’ private information, clinical research organizations undertake the arduous task of cleaning up the paperwork manually.
Gramener devised an NLP-driven data redaction solution for a global healthcare organization to tackle this problem. The solution uses Named Entity Recognition techniques to manage patients’ PHI (Protected Health Information) & PII (Personally Identifiable Information). There are multiple NLP use cases in healthcare, right from using NLP to anonymize clinical trail records to handling patients’ personal information.
Using an automated process that involves entity detection, extraction, relationship management, and anonymization, PrivacyAI reduces the turnaround time from days to hours. This helps the clinical study teams meet the stringent deadlines of regulatory bodies with relative ease.
Check out our unstructured analytics solutions that have helped top organizations make sense out of textual and image data.
Data Anonymization in the Healthcare Sector
Data anonymization has extensive use cases in protecting user information and their privacy. One of the critical examples in the healthcare sector, where clinical trials play a crucial role in rolling out new medicines and vaccines. When individual volunteers participate in clinical trials, it is essential to remove their identifiable links.
Patient-level health data is sensitive, requiring intense safeguarding from breaches. With the help of data anonymization, healthcare organizations can destroy links that connect old datasets with the new ones. It is also a crucial step to ensure transparency of the clinical data.
The best way to anonymize this data is by leveraging a macro. You can define the data, create a macro, and anonymize mode attributes. The next step is to pass attributes through anonymization macro. You can choose the different variables in the dataset you want to anonymize.
You can also standardize the data and maintain it in a change management system. However, there is a need to use the appropriate versioning methods and related approvals.
Data Anonymization in the Financial Industry
The financial industry has another use case of data anonymization. Financial businesses leverage personal data to offer highly customized services to clients. The customer insights also help them create scalable business models. However, the industry also remains highly vulnerable to cyber threats.
Hackers are always on the lookout to commit financial fraud by stealing bank and credit card details. Thus, there is a need to keep the data protected against vulnerabilities. At the same time, financial businesses also need to comply with the GDPR norms. Anonymizing data helps in protecting customer information.
Businesses also have the flexibility of using that data for analysis. The data will also remain compliant with all the necessary GDPR norms to ensure hassle-free operations.
Data Anonymization Pros
Here are the various advantages of opting for data anonymization:
Helps Maintain Business Reputation
Data anonymization helps businesses ensure compliance with the personal data of users. Data management principles vary based on countries and industries, leading to increased complexities. Organizations can thus comply with the norms and prevent situations where their reputation is at stake.
Prevents Data Exploitation
Data breaches can often be due to insider activities. It can become difficult for organizations to identify culprits when in-house personnel is involved. Data anonymization helps overcome this problem as only authorized individuals can access data through secure login and password.
Improves Governance
Accurate data enables better targeting of users through customized services. When you anonymize data, it adds to consistency and improves governance. You can also ensure the privacy of sensitive user information, which leads to excellent value addition for businesses.
Cons of Data Anonymization
While data anonymization has several advantages, there are some disadvantages as well. Most regulatory norms today require businesses to seek user permission to collect data. The data can be through personal information, IP addresses, cookies, and much more.
When businesses gather anonymous data without identifiers, it becomes difficult for them. They cannot get meaningful insights from such data and would not add much value. Similarly, such data will not help offer personalized services to clients.
Contact us for custom built low code data and AI solutions for your business challenges and check out unstructured data analytics solutions built for our clients, including Fortune 500 companies. Book a free demo right now.
