

Hi, I’m Murali Manohar. I’m working as a Data Scientist in Gramener’s AI Labs for a year now. Here, we have a brainstorming session called the Funnel where we work on pilots that we find interesting. In this audio analytics use case, we analyze the moods of characters in soap operas using background music to develop this machine learning solution.
Introduction
Remember how many Indian films contain creepy stares or actions of heroes? The BGM plays a huge role in spoon-feeding the audience that these actions are actually romantic.
I will base this article on the premise that the essential part of processing a video is its audio, despite the popular practice of processing video frames to identify expressions. I will also show you how we converted this theory into a working pilot on an Indian TV soap opera.
Video: Take a look at the video below to understand how a scene’s mood changes through BGM

What is Given to the AI System?
The video below (video frames without audio) is what we generally give as input to the AI system to identify the current scene’s atmosphere.
The Model should look at each frame, and identify the characters and their expressions. Let’s try to process this input, just as how an AI system would. Can you guess the atmosphere/mood of this scene from facial expressions?

Ok, we added the audio for you. How about now? Better? Even when the faces are blank, the Background Music (BGM) gives us a whole new perspective.

Not convinced yet? Let’s take a scenario where a person beats up a bunch of people. Here, AI will fail to notice whether it’s heroic or villainous because it doesn’t have any context or world knowledge that we possess.
So, just giving a video feed without audio doesn’t help.
When we are talking in terms of Indian TV serials (soap operas), every scene is filled with histrionics and loud BGMs to convey the situation of the scene. We leveraged this information to analyze the videos.
Step 1: Extracting Audio From Video
The differential factor between our method and existing methods comes in the first step — the input format to the system. As discussed above, the current video-analytics practice involves discarding audio and converting the video into frames/images, which are to be processed by current state-of-the-art neural networks.
Since we base our approach to show the rich information that the audio contains, we only consider the audio while discarding the video altogether.
Step 2: BGM extraction / Vocal separation
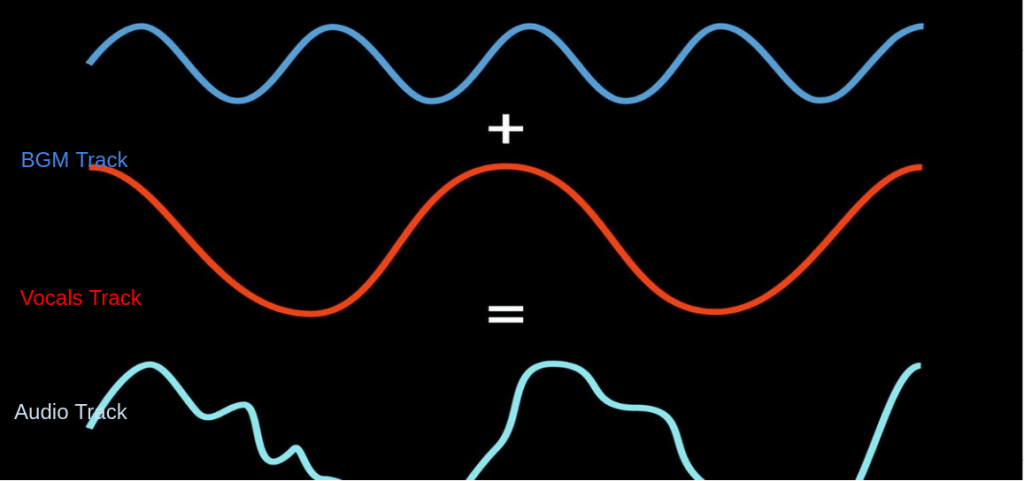
The audio consists of vocals and background-music. Although the vocals are informative, we discarded it for the vulnerability of error propagation. An error in any of the below steps would result in a totally different outcome.
- Converting speech to text.
- Text translation to English.
- Text classification
Accordingly, we extract different pieces of sound from the audio and store the BGM.
Step 3: Splitting BGM
We split the audio into smaller intervals based on the assumption that each mood’s BGM will have a fading entry and exit. After this process, we are left with tiny music files.

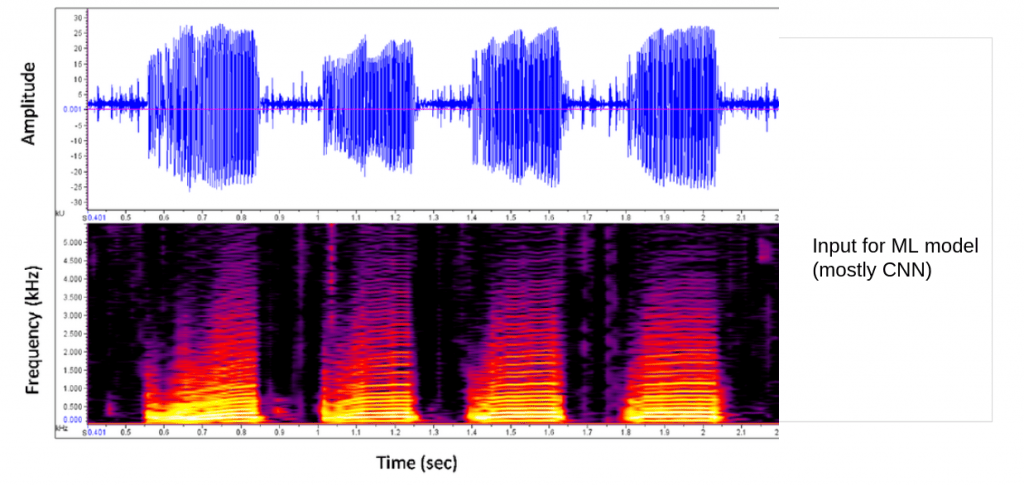
Step 4: Input to the AI model for predicting the mood
We convert these music files into a format suitable for the AI system. It can be a waveform, spectrogram, etc.
Results
We built an AI model that processes a video purely based on its audio. Here’s what we are able to get. Check out the audio analytics demo.
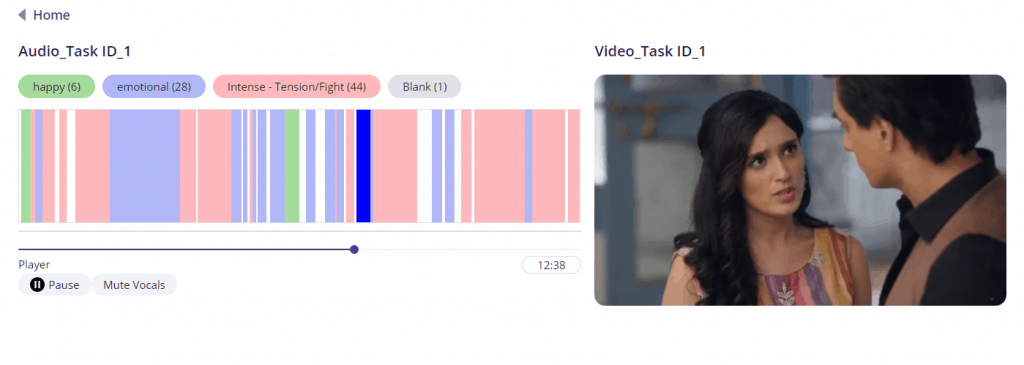
Figure: Predictions made on an audio file. Colors represent different moods. For brevity, we started with moods like happy, emotional/sentimental, intense/tension/fight.
While we don’t vouch for audio-only based systems, we want to emphasize that audio is a crucial aspect to consider while performing video analysis.
Future Work
My colleagues worked on CameraTrap, where we process motion sensor-based cameras to check if there are animals in the frame. For a similar premise, we are working on including audio to find interesting insights because there might be situations where we can detect poachers by vehicle sounds/shooting noises.
We can also find out if the animal is in pain. Vocals are also quite informative as language/text conveys more information. We will direct our future efforts towards exploiting vocals and also towards more nuanced moods in BGMs.
Check out Gramener’s Machine Learning Consulting and more AI solutions built on technologies such as Audio Analytics, Image recognition, Satellite Imagery, and Text Analytics.