Data is sensitive. Especially the data that holds personal information of people, their medical conditions, and their bank details have a high probability of getting hacked. To secure the miscarriage of data from the hands of hackers, data anonymization tools are suggested by experts. In the field of pharmaceuticals, banking, education, ministry, and much more, we’re presenting a list of the top best data anonymization tools and techniques.
Table of Contents
Data anonymization is a method of sanitizing information using tools to remove or encrypt Personally Identifiable Information (PII) from datasets. Its goal is to preserve the privacy of individuals who are subjects of the data.
Data anonymization prevents disclosure of private information during any form of transfer without compromising its analysis or evaluation across industries such as healthcare, finance, etc.
Critical insights, a cybersecurity company that analyzes data breaches reported by healthcare organizations to the US Health and Human Services (HHS) department, observed that, in 2021, cybersecurity breaches reached an all-time high, exposing the largest number of protected health information (PHI) records ever.
The healthcare attacks in 2018, affected 14 million individuals. In 2021, healthcare attacks affected a staggering 45 million individuals in the US, and the total number of individuals affected was 32% more than in 2020. The most common cause of breaches, IT incidents or hacking, increased by 10% in 2021.
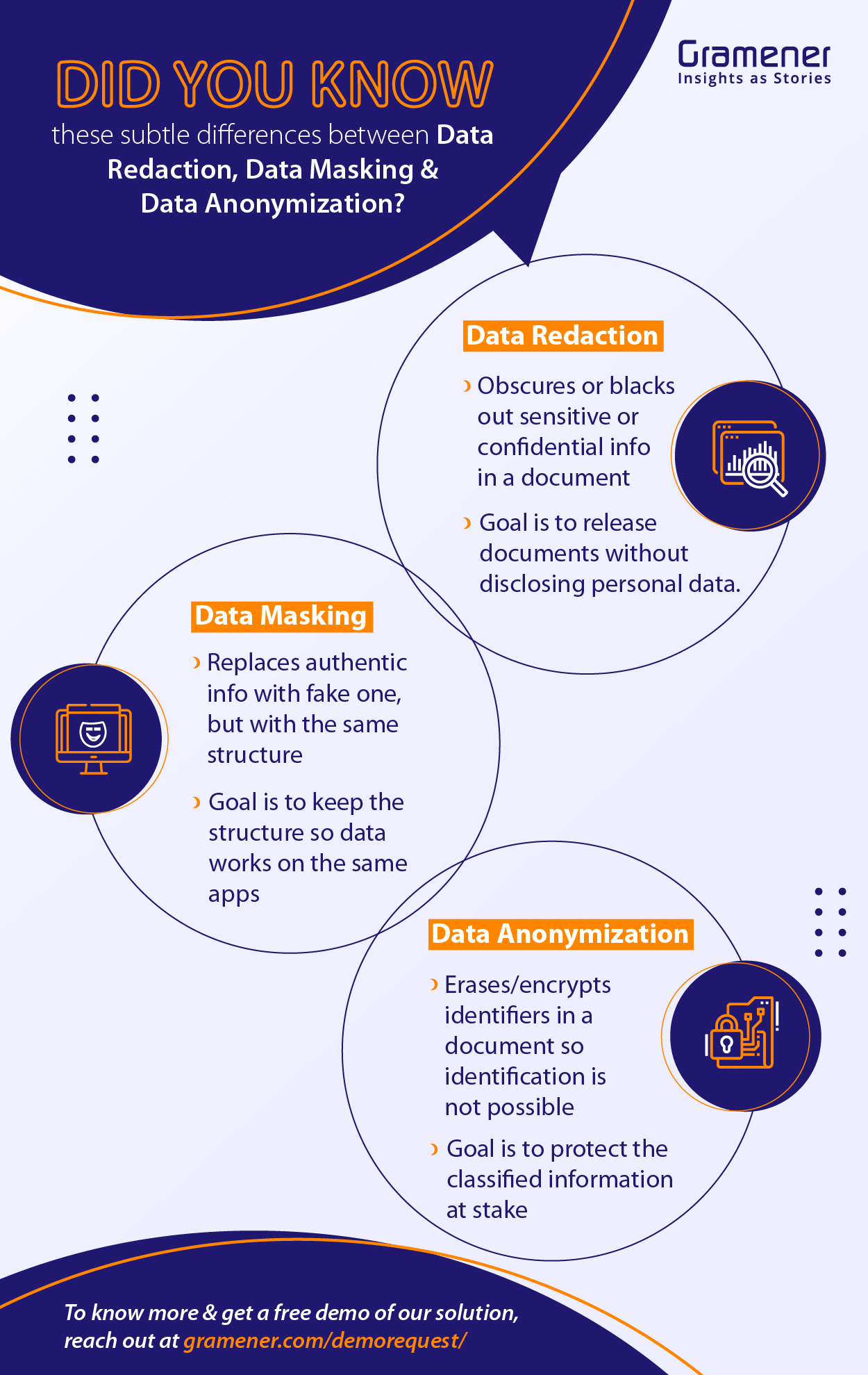
Anonymization converts data into a format where identification of individuals is unlikely. In contrast, redaction obscures all or a portion of the text to protect the data due to legal reasons, security or confidentiality. Using modern analytics techniques such as Natural Language Processing, data redaction hides and protects sensitive information. The use cases of NLP in the healthcare industry are wide-ranging and involve the use of natural language processing techniques to analyze unstructured data.
Data de-identification tools remove personally identifiable information to protect individual privacy. De-identified information may be re-associated with the original or mother data at a later date.
Data anonymization is indispensable to organizations that deal with personally identifiable information. It protects the integrity of data sharing.
The following are some of the best data anonymization tools in the market.
Created for one of the leading pharmaceutical clients, AInonymize, our data anonymization solution can redact patients’ private information from clinical trial documents. According to regulatory bodies like HIPPA, patients’ personally identifiable information should be kept hidden from third parties before sharing the studies from clinical trials.
Our data redaction solution has resulted in 97% time savings in the submission process and is expected to deliver savings of $1 million Per Annum.
Sensitive personal data can be anonymized using open-source software called ARX. It can transform data, analyze the use of output data, and support privacy and risk models.
The use of ARX involves training, clinical trial data sharing, research projects, and commercial big data analytics platforms. It consists of a graphical user interface that is intuitive and cross-platform. It can also handle large datasets on commodity hardware.
Clover DX’s data anonymization tool can render critical production-level data into anonymized data sets. It generates a highly reliable data set using a holistic approach to anonymizing the data. You can choose the extent to which the original data will be anonymized in the output.
This tool has a quick turnaround time and uses robust privacy techniques, such as injecting random data into the mix. Once the Anonymization Engine has been automated, you can anonymize your data at any time.
Docbyte uses Artificial Intelligence and machine learning in anonymizing data. Since the application does not follow any template, it can process content with a high degree of precision.
The tool can black out or blur images such as IDs or headshots and redact text using image-focused algorithms and object recognition.
Sensitive customer data stored in digital files is at risk of being copied or misused. Anonymizing or redacting on-the-spot guarantees compliance. Docbyte’s real-time processing anonymizes images and information as soon as they enter the system.
Once installed, the tool anonymizes the sensitive data within a system with minimal human intervention, ensuring compliance with GDPR and other regulations.
Personal data anonymized by Amnesia can be used for statistical analysis. It cannot be traced back to the original data.
Amnesia offers k-anonymity and km-anonymity to its data with minimal loss of quality during conversion. Datasets anonymized by Amnesia are GDPR compliant and are treated as statistics by the regulation standard.
Data anonymized by Amnesia is not restricted by GDPR or requires additional consent. This reduces the effort needed to extract value from them.
Amnesia can deliver anonymized data customized to the client’s needs through a graphical interface. Its anonymization engine can be integrated with any project using a REST API.
BizDataX offers a data masking toolbox to conceal identities within sensitive data while ensuring that developers and testers can still use the data. The sensitive data discovery module of BizDataX can automatically locate and check multiple systems and databases, offering detailed insights into hidden records and tables.
The tool helps keep the database and application level referential integrity intact, masking the data and extracting subsets of the data from production, enabling the creation of smaller databases.
The application is available on a 3-year subscription model or for a one-time license fee. Consumers can choose from a list of offerings public on the BizDataX website to customize a solution as per their needs.
The g9 Anonymizer is a fully programmable anonymization logic. It can be applied to multiple databases and is easily repeatable. If the data becomes too large, the tool can be programmed to delete the same automatically.
The g9 Anonymizer allows synthetic data to create data from scratch. It also allows the mixing of anonymization with synthetic data.
You can use the g9 Anonymizer to mask data with values from a text file or another column, incremental number sequences, or random numbers. You can also add Gaussian noise to randomize numeric data or create new permutations by shuffling data records.
The g9 Anonymizer allows its users to create new synthetic content for an empty database, reduce database size by deleting records, and apply the same masking across databases by creating a mapping file.
µ-ARGUS is a free data anonymization tool based on the programming language R, designed to support statistical analyses. ARGUS is an abbreviation for “Anti Re-identification General Utility System” and can create safe micro-data files.
The tool uses different statistical anonymization methods like top and bottom coding, micro aggregation, adding noise, randomization, local suppression, and global recoding (grouping of categories). µ-ARGUS can also be used to generate synthetic data.
sdcMicro is another data masking open-source tool. It is an R-package and can be used to create anonymized microdata.
sdcMicro was published in May 2018. It consists of a graphical user interface that can be used for various risk estimation methods.
Anonimatron is also an open-source data anonymization tool that pseudonymizes datasets. It can be used to do performance tests outside the client’s production environment or find a bug by generating pseudonymized production data.
Post release of GDPR, Anonimatron has been equipped with a feature that allows the anonymization of files.
It is the practice of altering data to hide values. You can mask data by duplicating the database and applying modification techniques like character or word substitution, encryption and character shuffling.
For instance, “x” or “*” symbols can replace the character values. It is not possible to detect or reverse engineer data masking.
When personal data is processed in such a manner that the information can no longer be traced back to its source without additional data, it is known as pseudonymization.
For the pseudonymization to be GDPR compliant, organizational and technical measures have to be taken to ensure that the additional information cannot be used to identify individuals. Said information also has to be kept separately.
Generalization is the process of deliberately removing portions of the data to make it less identifiable. The information can be modified into a broad area with boundaries or a set of ranges.
The goal of generalization is to retain a degree of data accuracy while eliminating some of the identifiers.
This technique, also known as permutation or shuffling, rearranges the dataset attribute values so that they do not correspond to the original records.
For example, swapping columns or attributes that contain identifier values like date of birth, etc., may have a more significant impact on anonymization than membership type values.
The application of techniques such as adding random noise or rounding off numbers to modify the original dataset is known as data perturbation. The perturbation has to be in proportion to the range of values.
A large base may render a dataset less useful. Conversely, a small base may weaken the anonymization process.
For instance, if we multiply a list of house numbers by 15, the resulting values still look credible. However, if we use the same method to anonymize an age column, the numbers appear fake.
Synthetic data consists of algorithmically generated information that is not connected to the actual data. Instead of altering the original dataset, synthetic data creates artificial datasets to protect the privacy and secure the data.
This involves the development of statistical models that are based on patterns in the original dataset. Statistical techniques such as linear regression, medians, and standard deviations can be used to create synthetic data.
Currently, medical professionals and researchers are gathering Covid-19 data that includes the name, age, gender, and location details of individuals. This information helps local health departments allocate testing resources, anticipate high-risk individuals, and track cases.
Unfortunately, should this data fall into the wrong hands, it could lead to misuse in the long run, such as discrimination against insurance or rent applications, etc.
Anonymization can help healthcare providers protect the personal information of Covid-19 patients, enabling them to continue with their everyday lives without hassle.
Data anonymization plays a crucial role in the success of clinical trials and breakthroughs in medical science.
A pharmaceutical sponsor, for example, may have conducted several clinical trials to develop a drug for a rare disease. At the same time, researchers at a leading university may be conducting studies on the same rare disease.
The university researchers could greatly benefit from the insights gained through the clinical trials, saving them months or maybe even years of time and effort.
Data anonymization helps protect the identifiable information of the patients who participated in the trials, enabling the pharmaceutical company to share its trial data with the university researchers in compliance with government regulations and industry advocates.
Financial firms are constantly looking for better ways to reduce their risks. One way to do this is to analyze customer data. Unfortunately, regulatory standards like GDPR require firms to obtain customer consent to use their data.
Thankfully, sufficiently anonymized data is not subject to regulatory compliance Financial institutions can leverage this data to extract value and gain insights.
Anonymized data can help financial companies detect and prevent fraud. In order to flag suspicious transactions and behavior, its trains intelligent models and smart systems.
Online retailers seek to improve how and when they reach their customers through their website, emails, social media, and digital advertisement. To refine their services and personalize user experience, digital agencies analyze customer information to gain insights.
Anonymization allows marketers to use customer data without breaching compliance.
Developers need to work with data to improve existing software, perform testing, and develop tools against real-life challenges. Unfortunately, development environments are not as secure as production environments.
In case of a breach, it could lead to the compromise of sensitive personal data. Thankfully, anonymized data can help protect personal and confidential data integrity.
Data anonymization plays an integral role in keeping the personal and sensitive information of individuals safe. In addition to protecting privacy, it also enables businesses and institutions to leverage the data to gain actionable insights and implement measures while adhering to strict regulatory standards.
Events such as the covid-19 global pandemic further remind us that advances like data anonymization can benefit humanity greatly, helping us overcome adversity and challenges, fostering innovation, and ushering in a new age of disruptive technologies.
Gramener is a data science, AI, and ML solutions company based in New Jersey that specializes in cutting-edge anonymization and redaction applications. We have helped industry leaders leverage machine learning in anonymizing data to drive growth and discoveries without violating the clauses of international regulatory standards.
Contact us for custom built low code data and AI solutions for your business challenges and check out pharma and life sciences AI solutions built for our clients, including Fortune 500 companies. Book a free demo right now.
NJBIZ has recognized Naveen Gattu, Founder and Chief Operating Officer of Gramener—A Straive Company, as… Read More
Computer vision (CV) has become an essential platform in the rapidly changing technology. It is… Read More
Are you struggling with lengthy and labour-intensive processes of manual inspection at your manufacturing? You… Read More
Managing smarter inventory is always challenging: too much stock consumes money, while too little results… Read More
The global food industry faces significant losses daily due to the spoilage of perishable goods.… Read More
In today’s fast-paced world of e-commerce and supply chain logistics, warehouses are more than just… Read More
This website uses cookies.
{kind=link}
Leave a Comment