At 1.8 million words, the Mahabharatha is one of the largest epics – roughly 10 times the size of the Iliad and Odyssey combined. At some level, this represents “big data”. Text is generally considered “unstructured” and therefore tough to analyze. But the growing field of text analytics and text visualization tell us that there’s a lot more structure to plain text than one might think.
To begin with, a word cloud can tell us a lot about the story.
The story is obviously about a battle between great kings and sons, with the principal characters being Arjuna, Pandu, Bhishma, Bharata, Karna, Duryodhana, Yudhishthira, Vaisampayama, etc. That’s decipherable without having to read the text.
The structure that we gleam out of it arises from a frequency distribution of the words – i.e. a count of which words occur how many times. The word cloud plots the words at a font size proportional to the frequency of occurrence.
Now what we know who’re the principal characters, the next questions are: where are they mentioned? Who’re closely related? etc.
Our Mahabharatha browser provides a simple interface to browse the full text of the Mahabharatha and find where the characters appear.
The Mahabharatha is made of 18 books, each with several sections. This visualisation shows each section as a block (the length of the block is proportional to the size of the section.) When you click on a character’s name, the positions in each section where they are mentioned are highlighted
This makes it easy to see where characters speak together (e.g. where does Kunti throw away Karna? Where does she meet him again? Did Draupadi really love Karna before her wedding? Was Arjuna really her favourite? Whom does Krishna favour? etc.) By clicking on the section, you can read the full text of that section.
The second question is, which characters are most closely related? Measuring closeness of characters is a difficult thing to do, even for humans. Fortunately, with text, we can rely on a proxy: how often are two characters found within a few words of each other.
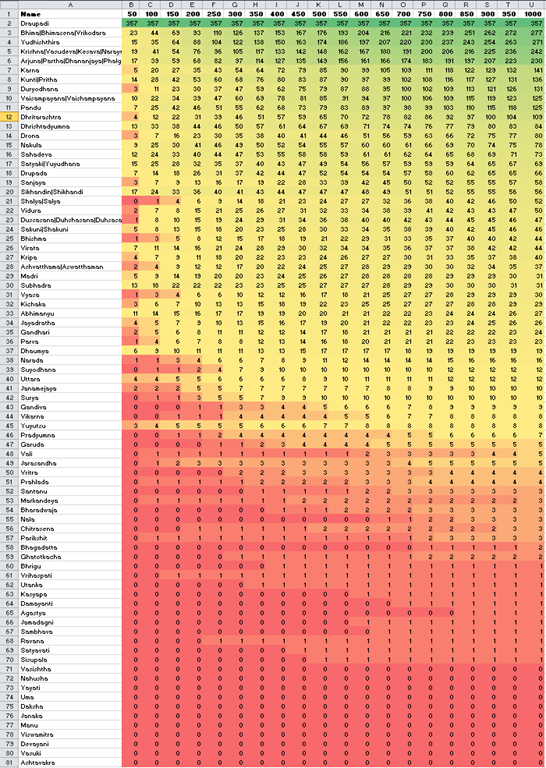
If we take Draupadi as a benchmark character and check how often various people are mentioned within a few words of her, here’s what the picture looks like:
Each row has the name of the character (along with aliases). The first column shows the number of times they’re mentioned within 50 words of her. The next shows how many times they’re mentioned within 100 words of her. And so on. (All within the same section.)
A visual inspection suggests that many characters start fading off at a distance of 200 words, so perhaps 200 might be a reasonable boundary to consider. (This is arbitrary. But based on our subsequent analysis, we find that this parameter does not impact the visual result too much.)
By plotting a network of their closeness, one can get some insights about the structure of the tale.
Yudhishthira is clearly at the centre of the plot. Arjuna, surprisingly, isn’t. Apart from his close relationship with Krishna and Bhishma, his interaction with other characters is not as well spread out (despite his popularity in the epic.) Contrary to popular opinion, Bhima is mentioned quite often, and is fairly well-networked. Nakula and Sahadeva remain peripheral characters. Gandhari is nearly outside of the network, except for her connection with her husband Dhritarashtra, sister-in-law Kunti, and brother-in-law Vidura (with whom she seems to converse much more than with her husband.)
Another way of looking at this picture is through a correlation matrix.
This shows each pair of characters and the number of times they occur within 200 words of each other. The closeness between Nakula and Sahadeva is very obvious; so are Drona & Kripa; Dhritharastra & Vidura; Arjuna & Krishna. Draupadi is mentioned with Dhrishtadhyumna more than anyone else.
You can also see the blocks breaking up into two clusters of sorts – on the bottom right are the primary characters. They interact a lot with each other. In the middle are secondary characters, who again interact amongst themselves; and then there are the narrators on the top left. This is in line with the Mahabharatha discussing several side-plots with secondary characters in parallel with the main plot. The story of Dhrishtadhyumna, of Satyaki, Nakula and Sahadeva’s conversations, etc are examples of these. In fact, in a larger scatterplot, you can see many more tales emerge, such as Nala & Damayanti; Nahusha & Yayati; Uma & Daksha; Vasishta & Vishwamitra; Chitrasena & Vikarna; Virata & Uttara; Dhrishtadhyumna & Shikhandin; Parva & Sambhava; even Ravana & Vali.
If you are interested in seeing the full correlation matrix with all major and minor characters, please reach us at contact@gramener.com.
NJBIZ has recognized Naveen Gattu, Founder and Chief Operating Officer of Gramener—A Straive Company, as… Read More
Computer vision (CV) has become an essential platform in the rapidly changing technology. It is… Read More
Are you struggling with lengthy and labour-intensive processes of manual inspection at your manufacturing? You… Read More
Managing smarter inventory is always challenging: too much stock consumes money, while too little results… Read More
The global food industry faces significant losses daily due to the spoilage of perishable goods.… Read More
In today’s fast-paced world of e-commerce and supply chain logistics, warehouses are more than just… Read More
This website uses cookies.
{kind=link}
{kind=link}
View Comments
This is Awesome!!! Great work!!! :)
This is interesting... !!!
Its a playful kind of informative one. Really appreciate your patience and good work. Quite Interesting and helpful for youngsters. Awesome and Good Work
Very interesting. Just curious what software was used to generate these analytics and if that software is publicly available.
Prabal, this was generated using the Gramener visualisation server. We haven't made it public yet, as we're licensing it. But we plan to release specific components to the public over the next few months. And example is the India map
Excellent use of Big data!
one of the most awesomest creations in recent times!!!
Its indeed an amazing work.. Nicely represented..However, I am trying to figureout the actual intent of this analysis and various data represenations.. May be that, am missing some skills to understand. Appreciate if you please briefly clarify the objective behind this data representations..
Very interesting analysis. ... Technique can be used to analyze social media data.
really appreciate your analysis ... !! nice work
Anand,
Considering the data-set and insight you want to illustrate (people, their relationships, and their closeness), I feel the circos like visualization is appropriate.
The arcs representing "people", and the chords connecting them the "relationship", with the thickness of the chord representing "closeness"
You could also use the d3.js representation for an open-source alternative.