This post is part of the output of the Bangalore Fifth Elephant Hacknight.
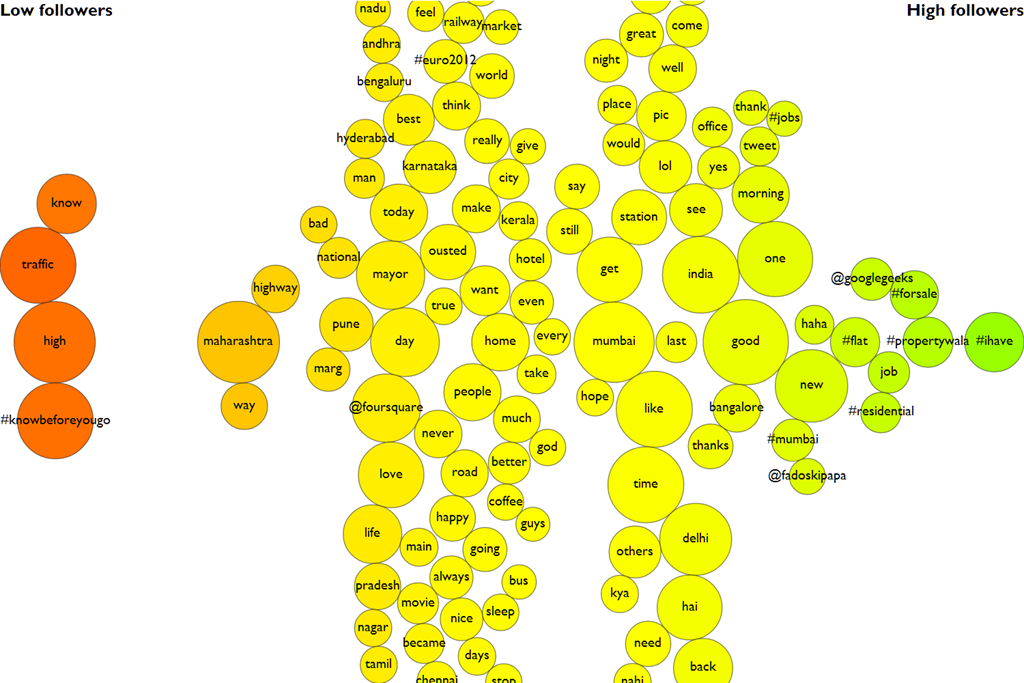
What you see above are the words most often used on Twitter by Indians. (Click for a larger image). The size of the bubble indicates how often the word is used.
We were looking at whether there are specific words that people with a large number of followers use, that are distinct from people with few followers. The words on the left (also coloured red) are used mainly by people with few followers. The words on the right (also coloured green) are mainly used by people with many followers.
(At this point, it’s worth discussing the dataset. These are 1 week’s worth of geocoded tweets, mainly around India (but including Pakistan, Nepal, etc.) It’s interesting that there were just 80,000 geocoded tweets in this period – and many of them were FourSquare entries.
It’s interesting that people )with low followers often talk about “know”, “high” and ‘”traffic”. People with many followers have significantly more hashtags. Whether this is a cause or an effect of having many followers is, of course, debatable. But the correlation is quite definite.
It also appears that those with more followers are polite. The “good morning”s and “thank you”s are quite to the right. Those with more followers are more likely to say “good” than “bad”, and vice versa. Perhaps there’s something about having Twitter followers that leads to happiness – or is it the other way around?
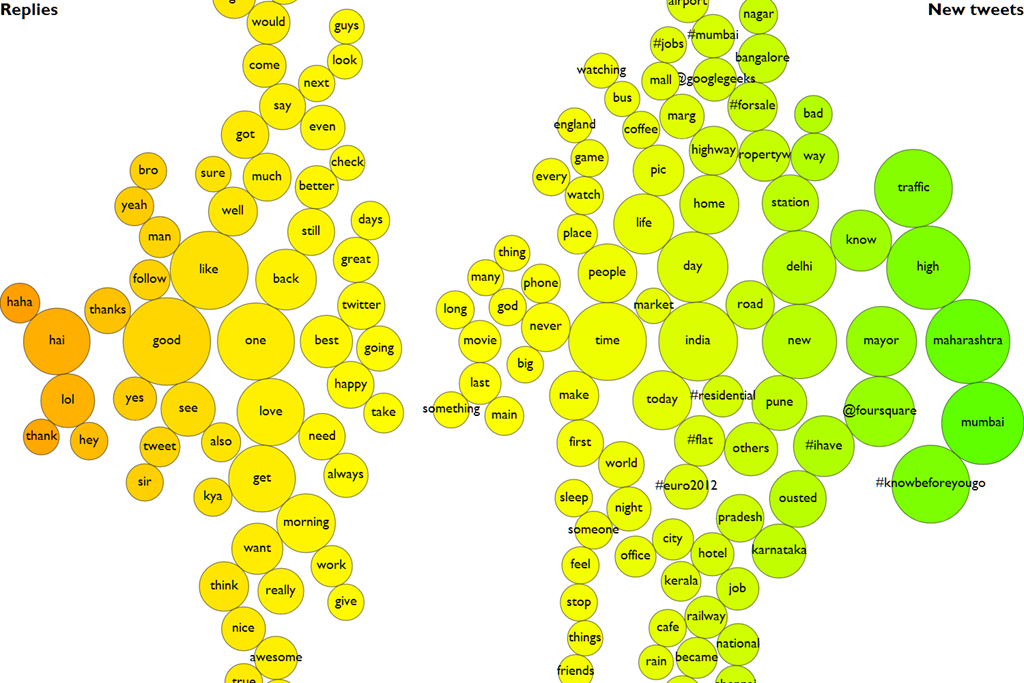
This picture shows you the words more often used in replies (on the left, in red) when compared to new tweets (on the right, in green).
“haha” and “lol” appear rather prominently in replies. Either folks who reply are an amused bunch, or it’s the funny tweets that get more replies. A lot of replies are also to thank people. The dominance of Mumbai, Maharashtra and Delhi on the right is easiest explained by the presence of the words “@foursquare” and “mayor” – most of these tweets appear to be FourSquare related.
The above shows the words used in the morning (up to 12 noon) vs the evening. Clearly, people mention “morning” in the morning – often, but not always, in the context of “good morning”. The evenings were, at least on this week, were dominated by Euro 2012.
The visualisation used above is a document contrast diagram. Each word is drawn as a bubble, whose size represents its frequency. The horizontal position determines whether the word is closer to one aspect or another – e.g. replies on the left vs new tweets on the right. This is a very quick and easy way of understanding what characterises an aspect (e.g. which words are often used with good vs bad), as well as the context in which words are used.
Industry 4.0 solutions originally had their genesis in manufacturing. “The Fourth Industrial Revolution, Industry 4.0,… Read More
Improvement in production performance can enhance supply chain efficacy. There is a continuous discourse around… Read More
Sshhhhhh, ChatGPT knows everything!! In 2023, Generative AI (GenAI) emerged as a major technology disruption… Read More
Generative AI holds immense promise for healthcare, leveraging large datasets to innovate medical imaging, treatment… Read More
NJBIZ has recognized Naveen Gattu, Founder and Chief Operating Officer of Gramener—A Straive Company, as… Read More
This website uses cookies.
{kind=link}
{kind=link}
{kind=link}
View Comments
twitter download does not give all tweets but only a random set. So, is it surely 80,000 or only twitter knows true number. Also, "good" or "bad" is not distinguishing polite from impolite. In fact low followers types use "love" and "best" more...just amusing, not shattering insights
GK Singh, these are geo-coded tweets from their Streaming API, and is a complete set. The reason it's about 80,000 is because most tweets in India are not geo-coded.
Agreed on "good" and "bad" not distinguishing polite from impolite. A lot more textual analysis needs to go into a deeper understanding. In the 6 hours we spent at the hacknight, we were focusing on prototyping a visualisation that could bring out the insights and demonstrate the process end-to-end -- rather than dive deep into any one area such as text analytics.